Patented Architecture-to-Gate Optimization
SilicorAI delivers AI-driven semiconductor optimization for advanced SoC designs—improving power, performance, area (PPA), and time-to-market through intelligent datapath architectures, low-power BLIB libraries, and the ARCEL AI-EDA optimization platform.
We combine deep semiconductor engineering with AI to accelerate full silicon lifecycle—from RTL and synthesis to floor planning, P&R, and post-silicon validation.
Up to 15–30% power reduction
Works on 65nm → 7nm (Bulk / FD-SOI / FinFET)
Zero Verification Overhead


ENTERPRISE VALIDATION
Zero Verification Overhead
Seamlessly integrate into large, rigid design flows without disrupting your verification cycles
No RTL Changes
Zero modifications to your RTL codebase. Works with your existing design as-is.
No Verification Effort
Eliminates the bottleneck of additional verification cycles. Your validation team stays on schedule.
Seamless Integration
Plug-and-play integration into existing EDA flows. No workflow disruption.
Enterprise validation teams save weeks of verification cycles.
SilicorAI's architecture-to-gate optimization delivers PPA improvements without requiring any changes to your RTL or verification testbenches—addressing one of the biggest bottlenecks in large-scale chip design.
OUR MISSION
Architecture-to-Gate PPA Optimization
for Advanced SoCs
SilicorAI improves power, performance, and area (PPA) for SoC designs through optimized datapath architectures, low-power BLIB libraries, and the ARCEL AI-EDA platform, delivering measurable silicon-level uplift without RTL or verification changes.
AI-driven selection
Plug and Play Product
Faster turnaround time
Zero verification overhead
Scales for advanced nodes
Works with any foundry or EDA ecosystem
Validated Across Industry Leaders
SilicorAI's patented architecture-to-gate optimization has been deployed and validated by leading semiconductor companies across diverse domains and architectures.
High-Performance FPGAs
Deployed on compute-intensive FPGA blocks for data center and networking applications.
RISC-V CPUs
Validated on RISC-V CPU cores and datapath logic for embedded and edge computing.
Automotive MCUs
Evaluated for automotive microcontrollers and SoCs requiring ultra-low power.
AI Accelerators & NPUs
Optimized MAC arrays, matrix engines, and systolic arrays for AI workloads.
Wireless & Modem SoCs
Deployed on wireless baseband datapaths and modem processing units.
Networking ASICs
Validated on packet processing datapaths and switch fabric architectures.
17 customer engagements across the United States, Japan, APAC, and India—including leading FPGA vendors, RISC-V CPU developers, automotive semiconductor companies, and wireless SoC manufacturers.
What We Offer
Complete technology stack: Low-power datapath architectures, BLIB cell libraries, ARCEL AI-EDA platform, and optimized datapath IP for compute-intensive workloads.
SilicorAI
Pioneering the future of semiconductor technology.
Works with standard EDA toolchains
BLIB: Low-Power Cell Libraries
Advanced leakage-aware standard cell library that reduces switching, leakage, and area. Results: Dynamic Power ↓ 12–67%, Leakage Power ↓ 20–163%, Area ↓ 10–15%. BLIB is NOT a replacement for foundry libraries; it is a workload-optimized companion library focused on datapath-driven power savings.
ARCEL: AI-EDA
Agentic AI system that dynamically adjusts PPA optimization decisions across RTL → gate → PnR → sign-off flow. 15–30% power reduction, 20–40% faster TAT.
Datapath IP Portfolio
Optimized adders, multipliers, MACs, and DSP blocks engineered for low switching, tight timing, and compact area. Delivers 15–30% power reduction and 10–20% area savings across datapath-intensive workloads.
Prototype & Pilot Fabrication
End-to-end support from architecture through silicon bring-up, with strategic partnerships worldwide.
SilicorAI
Pioneering the future of semiconductor technology.
BLIB: Low-Power Cell Libraries
Advanced leakage-aware standard cell library that reduces switching, leakage, and area. Results: Dynamic Power ↓ 12–67%, Leakage Power ↓ 20–163%, Area ↓ 10–15%. BLIB is NOT a replacement for foundry libraries; it is a workload-optimized companion library focused on datapath-driven power savings.
Datapath IP Portfolio
Optimized adders, multipliers, MACs, and DSP blocks engineered for low switching, tight timing, and compact area. Delivers 15–30% power reduction and 10–20% area savings across datapath-intensive workloads.
ARCEL: AI-EDA
Agentic AI system that dynamically adjusts PPA optimization decisions across RTL → gate → PnR → sign-off flow. 15–30% power reduction, 20–40% faster TAT.
Prototype & Pilot Fabrication
End-to-end support from architecture through silicon bring-up, with strategic partnerships worldwide.
Where We Shine
Peak benefits at 16nm/14nm/12nm/7nm where leakage + dynamic imbalance is greatest.
AI accelerators & NPUs
DSP-heavy blocks
RISC-V CPU internal datapaths
Graphics/Compute arrays
Wireless + modem datapaths
Networking switch/packet datapaths
Industries We Empower
Transforming diverse sectors with cutting-edge semiconductor technology.

Edge AI & IoT
Smart devices and connected systems
Consumer Electronics
Mobile and wearable technology
AI Datacenters
Hyper Scale Data center

Research Institutions
Academic and research innovation

Defense & Aerospace
Mission-critical applications
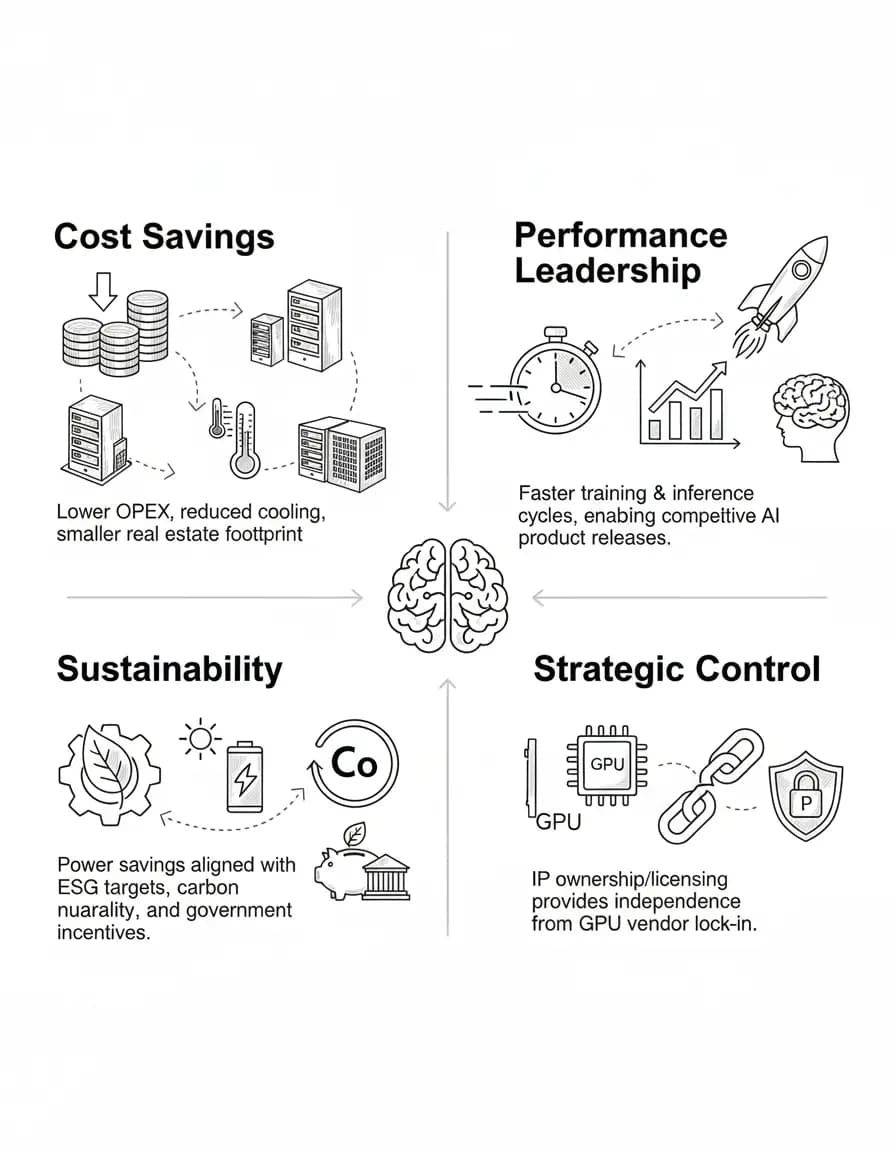
Why Partner with SilicorAI?
Only Vendor Optimizing PPA from Architecture Through Gate-Level: Addressing Power, Performance, and Area (PPA) from the architecture level to gate level, not just within individual EDA stages.
Zero RTL Changes → Zero Verification Overhead: Our products are non-intrusive and integrate seamlessly into existing flows, requiring no additional RTL edits or verification effort.
Demonstrated Improvements at 65/40/28/16/14/12/7nm: Proven across multiple nodes, with higher gains at advanced nodes (16nm, 14nm, 12nm, 7nm) where leakage and dynamic power are hardest to optimize.
Up to 15–30% Power Reduction and 10–15% Area Improvement: Typical evaluation results vary by design, node, and workload.
Works Across Major Tools: Compatible with Synopsys (DC, Fusion Compiler, PT), Cadence (Genus, Innovus, Tempus), and Siemens (Aprisa).
Protected by Granted U.S. Patent Portfolio: Validated intellectual property protecting our core innovations.
Proven Across 17 Customers Worldwide: Tested & validated across US, Japan, APAC, and India with consistent PPA improvements.
Works with All Architectures: CPUs, GPUs, NPUs, AI accelerators, DSPs, wireless, networking, and RISC-V architectures.
Future-Proof: Patented architecture-driven model scales its PPA benefits deeper into advanced nodes (7nm, 5nm, and below).
Global Customer Footprint
SilicorAI collaborates with customers across the United States, Japan, APAC, and India—with 17 total engagements spanning POCs, evaluations, and joint optimization projects.
4 regions 17 Ongoing customer engagements
Loading map...
United States
Total Engagements
7
Key Activities
POCs, Optimization, and Co-Validation for high-performance FPGA, RISC-V CPU, DSP, and specialized Optical/Analytics silicon.
Japan
Total Engagements
2
Key Activities
Evaluations focused on Consumer and Automotive MCU/SoC suitability.
APAC
Total Engagements
4
Key Activities
Combination of POCs and Evaluations targeting CPU/DSP IP and large-scale ASIC/HPC architectures.
India
Total Engagements
4
Key Activities
POCs, Joint Technical Work, and Evaluations across Wireless, EDA, and Telecom ASIC design domains.
Trusted by Global Semiconductor Innovators
Engineers across the United States, Japan, APAC, and India rely on SilicorAI to deliver realistic, architecture-level PPA gains—without disrupting RTL or verification flows.
United States · ARCEL AI-EDA Platform
POC — High-Performance FPGA Compute Block
Director of Silicon Architecture, U.S. FPGA Company
"ARCEL helped us uncover architecture choices that our tools were not exploring. We saw meaningful reductions in switching activity on a compute-critical block, and the integration had zero disruption on our RTL or verification. For a two-week POC, the insight was extremely valuable."
Testimonials are anonymized and NDA-safe; roles and regions are representative of real customer engagements.